

Total runs:
59.7M
Run Growth:
-13.9M
Growth Rate:
-23.90%


Language model:
bert-base-cased
Language:
German
Training data:
Wiki, OpenLegalData, News (~ 12GB)
Eval data:
Conll03 (NER), GermEval14 (NER), GermEval18 (Classification), GNAD (Classification)
Infrastructure
: 1x TPU v2
Published
: Jun 14th, 2019
Update April 3rd, 2020 : we updated the vocabulary file on deepset's s3 to conform with the default tokenization of punctuation tokens. For details see the related FARM issue . If you want to use the old vocab we have also uploaded a "deepset/bert-base-german-cased-oldvocab" model.
See https://deepset.ai/german-bert for more details
batch_size = 1024
n_steps = 810_000
max_seq_len = 128 (and 512 later)
learning_rate = 1e-4
lr_schedule = LinearWarmup
num_warmup_steps = 10_000
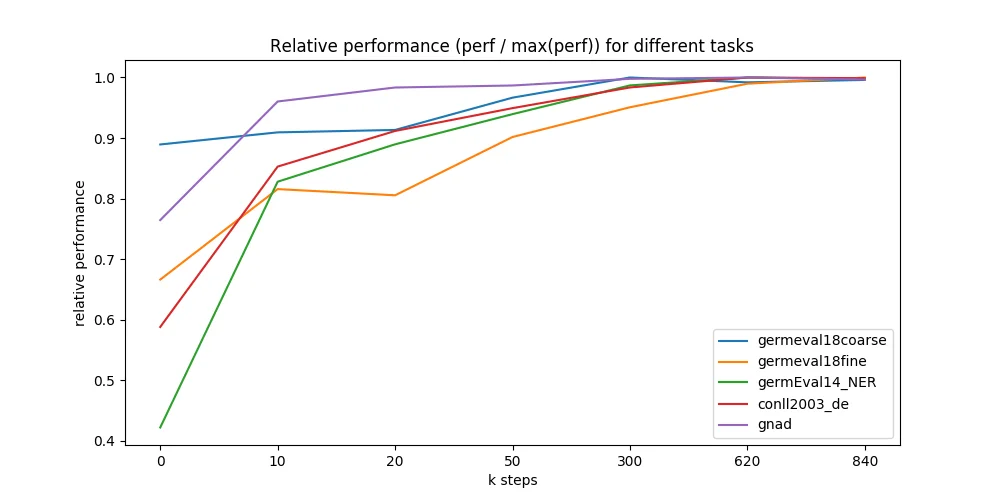
During training we monitored the loss and evaluated different model checkpoints on the following German datasets:
Even without thorough hyperparameter tuning, we observed quite stable learning especially for our German model. Multiple restarts with different seeds produced quite similar results.

We further evaluated different points during the 9 days of pre-training and were astonished how fast the model converges to the maximally reachable performance. We ran all 5 downstream tasks on 7 different model checkpoints - taken at 0 up to 840k training steps (x-axis in figure below). Most checkpoints are taken from early training where we expected most performance changes. Surprisingly, even a randomly initialized BERT can be trained only on labeled downstream datasets and reach good performance (blue line, GermEval 2018 Coarse task, 795 kB trainset size).
branden.chan [at] deepset.ai
timo.moeller [at] deepset.ai
malte.pietsch [at] deepset.ai
tanay.soni [at] deepset.ai
![]()
We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work: