

Total runs:
690.9K
Run Growth:
-85.4K
Growth Rate:
-12.35%
Base model: Qwen/Qwen3-Coder-Next
This repo trims 34% of the experts (512 → 336);
The model format and serving setup (vLLM/SGLang versions and launch commands) match the original release.
2026-02-05
1. Initial commit
| File Size | Last Updated |
|---|---|
99 GiB
|
2026-02-05
|
from huggingface_hub import snapshot_download
snapshot_download('QuantTrio/Qwen3-Coder-Next-E336', cache_dir="your_local_path")
Today, we're announcing Qwen3-Coder-Next , an open-weight language model designed specifically for coding agents and local development. It features the following key enhancements:
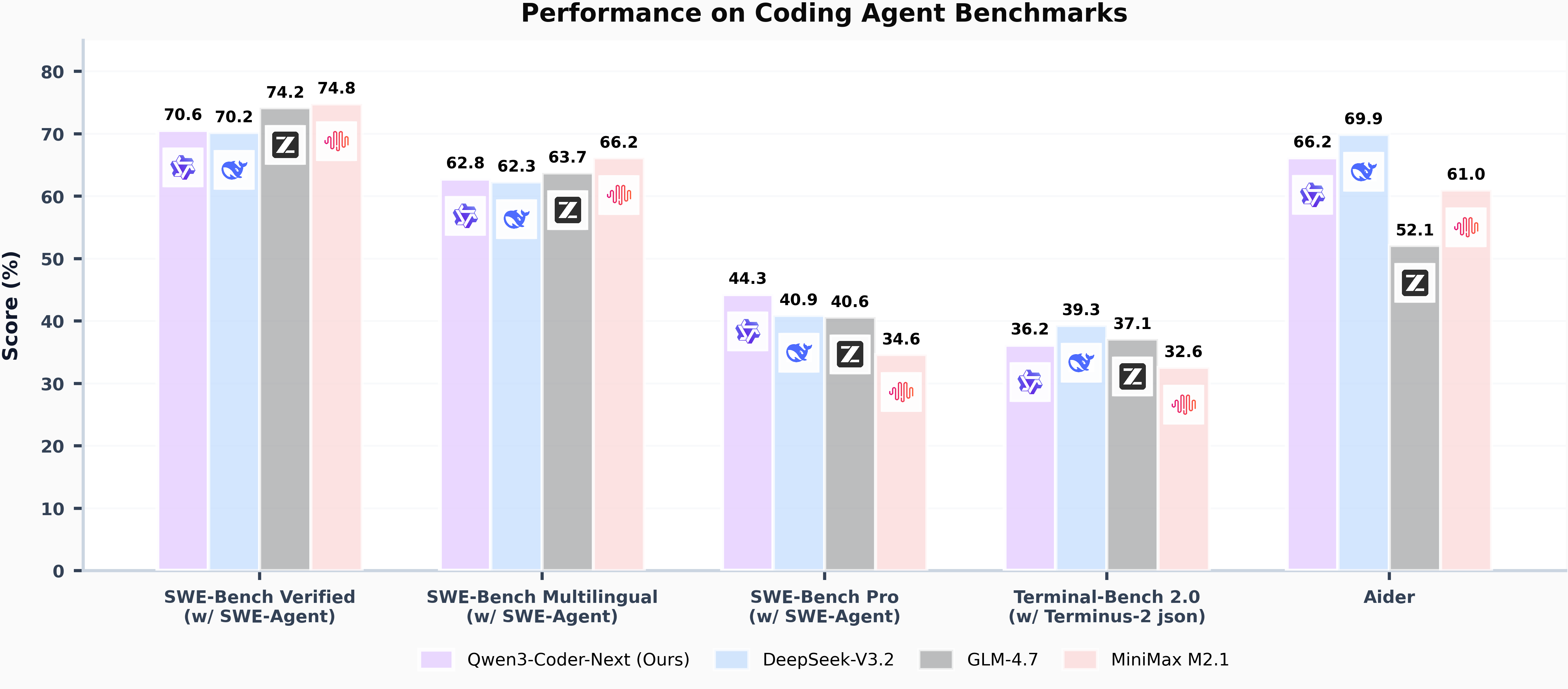
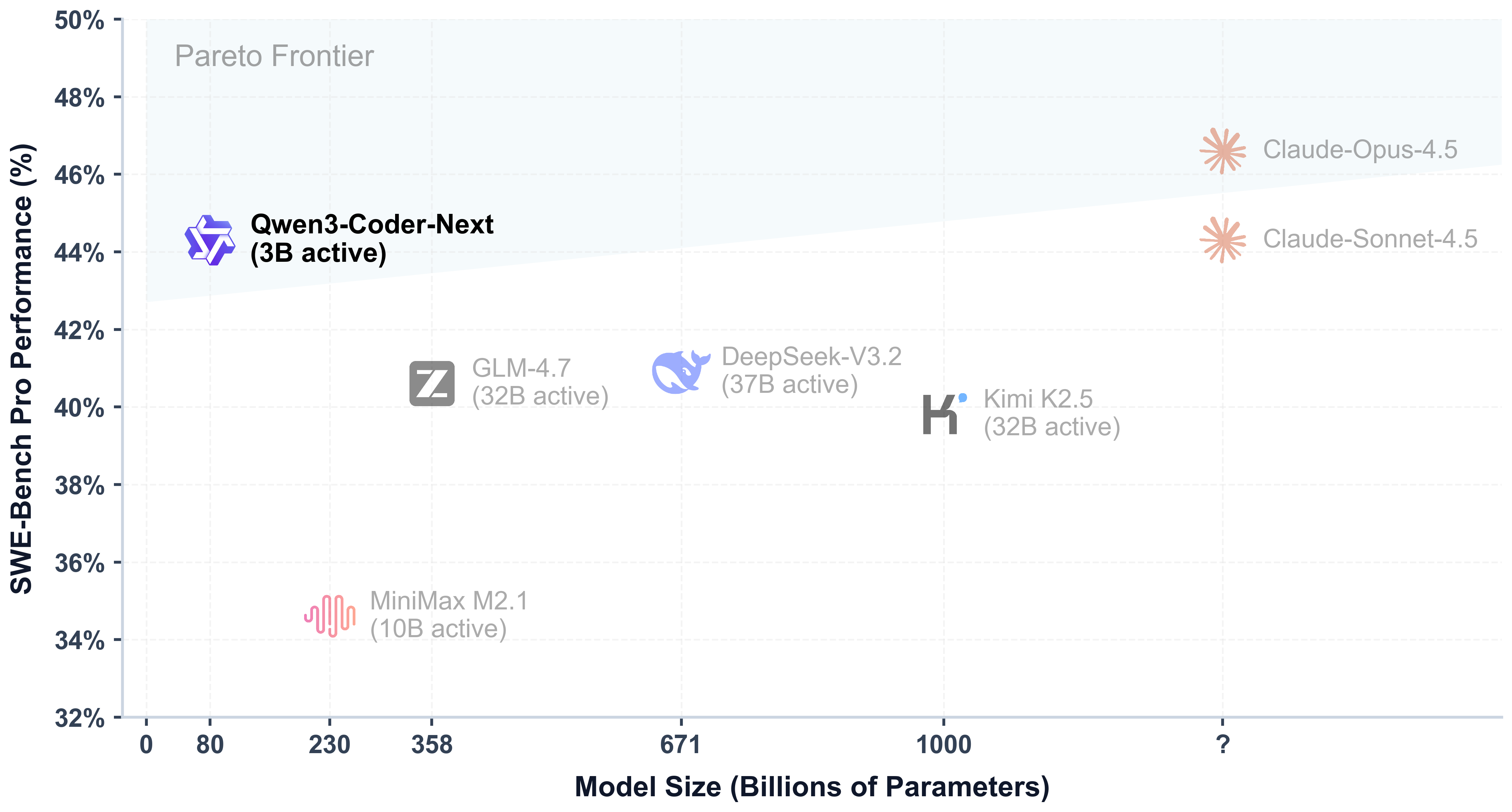
Qwen3-Coder-Next has the following features:
NOTE: This model supports only non-thinking mode and does not generate
<think></think>
blocks in its output. Meanwhile, specifying
enable_thinking=False
is no longer required.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our blog , GitHub , and Documentation .
We advise you to use the latest version of
transformers
.
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-Next"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Write a quick sort algorithm."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=65536
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as
32,768
.
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
For deployment, you can use the latest
sglang
or
vllm
to create an OpenAI-compatible API endpoint.
SGLang is a fast serving framework for large language models and vision language models. SGLang could be used to launch a server with OpenAI-compatible API service.
sglang>=v0.5.8
is required for Qwen3-Coder-Next, which can be installed using:
pip install 'sglang[all]>=v0.5.8'
See its documentation for more details.
The following command can be used to create an API endpoint at
http://localhost:30000/v1
with maximum context length 256K tokens using tensor parallel on 4 GPUs.
python -m sglang.launch_server --model Qwen/Qwen3-Coder-Next --port 30000 --tp-size 2 --tool-call-parser qwen3_coder
The default context length is 256K. Consider reducing the context length to a smaller value, e.g.,
32768, if the server fails to start.
vLLM is a high-throughput and memory-efficient inference and serving engine for LLMs. vLLM could be used to launch a server with OpenAI-compatible API service.
vllm>=0.15.0
is required for Qwen3-Coder-Next, which can be installed using:
pip install 'vllm>=0.15.0'
See its documentation for more details.
The following command can be used to create an API endpoint at
http://localhost:8000/v1
with maximum context length 256K tokens using tensor parallel on 4 GPUs.
vllm serve Qwen/Qwen3-Coder-Next --port 8000 --tensor-parallel-size 2 --enable-auto-tool-choice --tool-call-parser qwen3_coder
The default context length is 256K. Consider reducing the context length to a smaller value, e.g.,
32768, if the server fails to start.
Qwen3-Coder-Next excels in tool calling capabilities.
You can simply define or use any tools as following example.
# Your tool implementation
def square_the_number(num: float) -> dict:
return num ** 2
# Define Tools
tools=[
{
"type":"function",
"function":{
"name": "square_the_number",
"description": "output the square of the number.",
"parameters": {
"type": "object",
"required": ["input_num"],
"properties": {
'input_num': {
'type': 'number',
'description': 'input_num is a number that will be squared'
}
},
}
}
}
]
from openai import OpenAI
# Define LLM
client = OpenAI(
# Use a custom endpoint compatible with OpenAI API
base_url='http://localhost:8000/v1', # api_base
api_key="EMPTY"
)
messages = [{'role': 'user', 'content': 'square the number 1024'}]
completion = client.chat.completions.create(
messages=messages,
model="Qwen3-Coder-Next",
max_tokens=65536,
tools=tools,
)
print(completion.choices[0])
To achieve optimal performance, we recommend the following sampling parameters:
temperature=1.0
,
top_p=0.95
,
top_k=40
.
If you find our work helpful, feel free to give us a cite.
@techreport{qwen_qwen3_coder_next_tech_report,
title = {Qwen3-Coder-Next Technical Report},
author = {{Qwen Team}},
url = {https://github.com/QwenLM/Qwen3-Coder/blob/main/qwen3_coder_next_tech_report.pdf},
note = {Accessed: 2026-02-03}
}