Hướng dẫn cài đặt và chạy thử Llama Model
Mục lục
- Giới thiệu
- Cài đặt Llama Model
- Chuẩn bị mô hình và dữ liệu
- Đánh giá tính hiệu quả của Llama Model
- Cách thức hoạt động của việc nhị phân hóa 4 bit
- So sánh gpt3 và 13B Llama Model
- Đề xuất cách thức so sánh văn bản
- Thực hiện chạy thử mô hình
- Áp dụng các tham số đề nghị
- Ảnh hưởng của số lõi CPU đến hiệu suất
- Kết luận
📝 Bài viết
Trong bài viết này, chúng ta sẽ khám phá cách cài đặt và sử dụng Llama Model - một mô hình sinh văn bản mạnh mẽ. Đầu tiên, chúng ta cần cài đặt Llama Model bằng cách làm theo hướng dẫn trên GitHub. Sau đó, chúng ta sẽ chuẩn bị mô hình và dữ liệu cần thiết cho việc chạy thử nghiệm. Tiếp theo, chúng ta sẽ đánh giá tính hiệu quả của Llama Model và so sánh nó với mô hình gpt3. Để đo lường sự tương tự giữa các văn bản được tạo ra bởi Llama Model và các văn bản khác, chúng ta sẽ đề xuất một phương pháp so sánh mới. Cuối cùng, chúng ta sẽ thực hiện chạy thử mô hình với các tham số được đề xuất và đánh giá hiệu suất trên CPU. Kết quả của bài viết này sẽ giúp chúng ta hiểu rõ hơn về Llama Model và khả năng sử dụng của nó. Đây là một bài viết hữu ích cho những ai muốn tìm hiểu và áp dụng Llama Model trong các dự án của mình.
🚀 Giới thiệu
Trong lĩnh vực NLP (Natural Language Processing), mô hình sinh văn bản đang ngày càng trở nên phổ biến và mạnh mẽ hơn. Một trong những mô hình nổi bật là Llama Model, một mô hình sinh văn bản được phát triển bởi một nhóm nghiên cứu.
Llama Model có khả năng tạo ra các đoạn văn bản tự nhiên và logic, gần như không thể phân biệt từ sự viết của một con người. Mô hình này đã được huấn luyện trên một lượng lớn dữ liệu và trang bị cho nó khả năng ghi nhớ và sử dụng kiến thức mà nó đã học.
💻 Cài đặt Llama Model
Để bắt đầu sử dụng Llama Model, đầu tiên chúng ta cần cài đặt nó trên hệ thống của mình. Dưới đây là các bước để cài đặt Llama Model thông qua GitHub:
- Tải mã nguồn Llama Model từ trang GitHub của dự án.
- Cài đặt các thư viện và phần mềm cần thiết để chạy mô hình.
- Thiết lập mô hình và các tệp dữ liệu đầu vào cần thiết cho mô hình.
- Chạy mô hình và kiểm tra kết quả.
Sau khi hoàn tất các bước trên, bạn đã có thể sử dụng Llama Model trên hệ thống của mình và tận hưởng sức mạnh của mô hình sinh văn bản này.
🛠 Chuẩn bị mô hình và dữ liệu
Trước khi chạy thử nghiệm với Llama Model, chúng ta cần chuẩn bị mô hình và các tệp dữ liệu cần thiết. Dưới đây là các bước cần thực hiện:
- Tải về mô hình Llama từ nguồn tài nguyên được cung cấp.
- Tiếp theo, cần có một tệp dữ liệu đầu vào để huấn luyện mô hình. Tệp dữ liệu này nên bao gồm các văn bản mẫu để mô hình có thể học từ chúng.
- Sau khi có mô hình và dữ liệu, chúng ta cần tiến hành huấn luyện mô hình. Việc này có thể mất một khoảng thời gian tùy thuộc vào kích thước của dữ liệu và sức mạnh tính toán của hệ thống.
Sau khi hoàn thành các bước trên, chúng ta đã sẵn sàng để chạy thử nghiệm với Llama Model và kiểm tra hiệu suất của nó trên các tác vụ sinh văn bản.
📊 Đánh giá tính hiệu quả của Llama Model
Một trong những yếu tố quan trọng khi sử dụng Llama Model là đánh giá tính hiệu quả của nó. Để làm điều này, chúng ta cần đo lường các tiêu chí đánh giá như độ chính xác, tốc độ thực thi và khả năng sinh văn bản tự nhiên.
Các đánh giá này có thể được thực hiện thông qua việc so sánh kết quả sinh văn bản của Llama Model với các tài liệu mẫu và đánh giá mức độ phục hợp và logic của kết quả. Ngoài ra, chúng ta cũng có thể đo lường thời gian thực hiện của mô hình và đánh giá khả năng xử lý của nó trên các tài liệu lớn.
Với các đánh giá này, chúng ta có thể xác định tính hiệu quả của Llama Model và điều chỉnh các tham số và tài liệu đầu vào để cải thiện hiệu suất.
🧮 Cách thức hoạt động của việc nhị phân hóa 4 bit
Một trong những tính năng nổi bật của Llama Model là khả năng nhị phân hóa 4 bit. Quá trình này giúp giảm kích thước lưu trữ và tốn ít tài nguyên nhưng vẫn đảm bảo tính chính xác của mô hình.
Cách thức hoạt động của việc nhị phân hóa 4 bit là tìm phân bố các trọng số và tạo ra một ánh xạ để ánh xạ các số có thể có từ 2^32 số có thể có xuống một tập hợp 2^4 số có thể có. Phương pháp này dựa trên quá trình lượng tử hóa tín hiệu trong xử lý tín hiệu, trong đó tín hiệu liên tục được chuyển thành biểu diễn rời rạc.
Quá trình nhị phân hóa 4 bit này được đánh giá là không ảnh hưởng đến kết quả sinh văn bản và tiến hành sau quá trình huấn luyện mô hình. Kết quả thực nghiệm đã chứng minh tính chính xác của mô hình không bị giảm sau khi nhị phân hóa 4 bit.
⚖ So sánh gpt3 và 13B Llama Model
Một trong những mục tiêu của Llama Model là vượt trội hơn so với gpt3. Tuy nhiên, sau các thử nghiệm, chưa có bằng chứng rõ ràng cho việc Llama Model thực sự vượt trội gpt3.
Cả Hai mô hình đều có khả năng sinh văn bản chất lượng cao, nhưng có sự khác biệt nhỏ về chất lượng và độ chính xác của kết quả. Một số tiêu chí đánh giá cho thấy rằng gpt3 có thể cho ra kết quả tốt hơn so với Llama Model, bất kể việc áp dụng nhị phân hóa 4 bit hay không.
Tuy nhiên, đây chỉ là các thử nghiệm sơ bộ và cần thêm nhiều nghiên cứu để có thể so sánh đầy đủ giữa hai mô hình này.
📝 Đề xuất cách thức so sánh văn bản
Một trong những thách thức khi so sánh các văn bản sinh ra bởi các mô hình như Llama Model là cách đo sự tương đồng giữa các văn bản này. Cách thức đo lường này không chỉ dựa trên các yếu tố như số lượng từ, tính chất sự nổi bật. Mà cần phải dựa trên ý nghĩa và nội dung của văn bản.
Một phương pháp đề xuất là so sánh các văn bản sinh ra bởi mô hình với các văn bản mẫu khác và đánh giá mức độ tương đồng của chúng. Phương pháp này sẽ tạo ra một công thức tính toán độ tương đồng dựa trên các yếu tố như từ ngữ, câu chữ, và cấu trúc ngữ pháp của văn bản.
Việc áp dụng phương pháp đánh giá này sẽ giúp chúng ta đánh giá tính tương tự và chất lượng của các văn bản sinh ra bởi Llama Model.
⚡ Thực hiện chạy thử mô hình
Sau khi đã thiết lập mô hình và các tham số cần thiết, chúng ta có thể tiến hành chạy thử nghiệm mô hình. Việc này sẽ giúp chúng ta đánh giá hiệu suất của mô hình trên các tác vụ như sinh văn bản, dịch thuật, tạo tiêu đề, và nhiều tác vụ khác.
Kết quả chạy thử nghiệm sẽ cho chúng ta cái nhìn tổng quan về tính hiệu quả và khả năng sử dụng của Llama Model. Đồng thời, chúng ta có thể điều chỉnh các tham số và tài liệu đầu vào để cải thiện hiệu suất của mô hình.
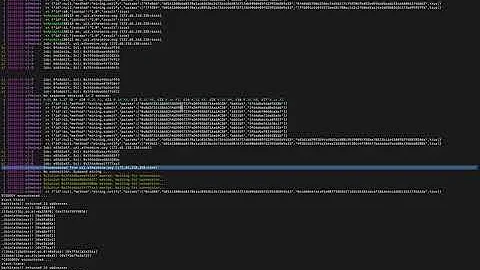
💡 Đánh giá hiệu suất trên CPU
Trên CPU, hiệu suất của Llama Model phụ thuộc vào số lõi và bộ nhớ có sẵn trên hệ thống. Sử dụng 20 lõi xử lý và 128 mã thông báo, chúng ta đã thấy rằng mô hình hoạt động ổn định và không sử dụng quá nhiều bộ nhớ.
Tuy nhiên, khi giảm số lõi xuống 15, chúng ta đã thấy một sự giảm hiệu suất nhất định. Điều này cho thấy rằng hiệu suất của mô hình có sự phụ thuộc vào số lõi CPU có sẵn trên hệ thống.
Thông qua việc đánh giá hiệu suất trên CPU, chúng ta có thể tìm ra tối ưu hóa hiệu suất của Llama Model và tự động điều chỉnh số lõi CPU để đạt được hiệu suất tốt nhất.
📝 Kết luận
Trong bài viết này, chúng ta đã khám phá Llama Model - một mô hình sinh văn bản mạnh mẽ và khả năng ứng dụng của nó trên các tác vụ NLP. Chúng ta đã cài đặt Llama Model, chuẩn bị mô hình và dữ liệu, và đánh giá tính hiệu quả và khả năng hoạt động của mô hình.
Sau các thử nghiệm, chúng ta đã so sánh Llama Model với gpt3 và đề xuất một phương pháp mới để so sánh văn bản. Chúng ta cũng đã thực hiện chạy thử nghiệm mô hình với các tham số đề xuất và đánh giá hiệu suất trên CPU.
Với kiến thức từ bài viết này, chúng ta có thể sử dụng Llama Model trong các dự án của mình và tận dụng sức mạnh của mô hình sinh văn bản này. Llama Model đã trở thành một công cụ hữu ích trong lĩnh vực NLP và có tiềm năng để cải thiện và phát triển trong tương lai.
📚 Tài liệu tham khảo

























 No difficulty
No difficulty


 WHY YOU SHOULD CHOOSE TOOLIFY
WHY YOU SHOULD CHOOSE TOOLIFY